DevOps With Bitbucket Pipelines
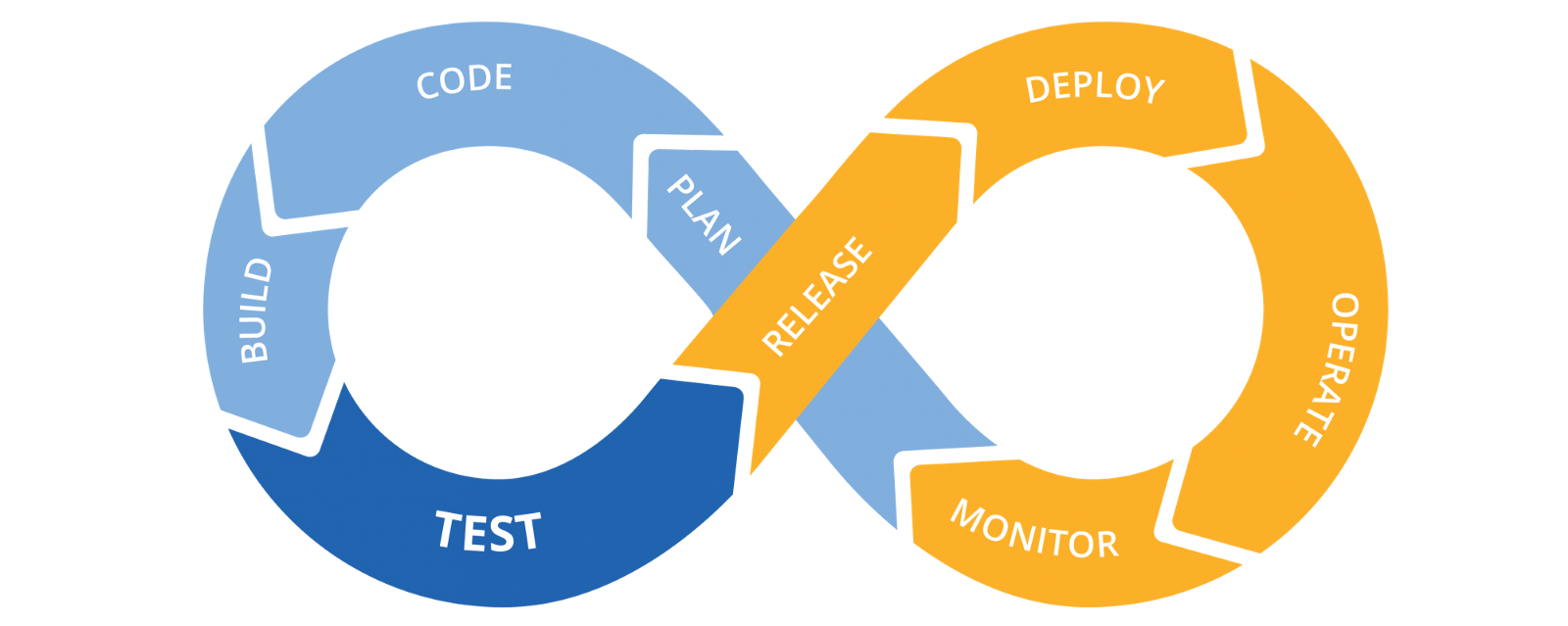
Continuity in modern software development allows for frequent and consistent product release cycles guaranteeing your business ability to react to market changes whilst keeping your team productive.
In this session we’ll take a closer look at the guiding principles of continuous integration, continuous delivery and continuous deployment and highlight their key differences and their application using Bitbucket Pipelines.
image: node:10.15.0
pipelines:
default:
- step:
script:
- node -v
Overview of DevOps Culture
DevOps combines the operation tools and agile engineering practices to encourage collaboration between development and operations teams.
DevOps is driven by shared responsibility and increased collaboration between teams.
A development team that shares responsibility with the operations team can come up with simplified ways of managing deployments and monitoring production services for greater feedback.
The operations team can also work closely with the development team to understand the operational needs for a system and adoption of new tools.

DevOps culture blurs the lines between various teams, a common abuse of this culture is creating a DevOps Team .
Another core driving factor in DevOps is autonomy in teams. Developers and Ops team need to be able to make decisions and apply changes without having to go through a complex decision-making process.
At the core of DevOps is Automation. Automation removes chances of human error that may creep in during testing, configuration management and deployment scenarios.
DevOps pipeline
Continuous Integration
Continuous Integration advocates for automated building and testing before merge with the main branch. Depending on the branch work-flow, the code will have to be merged with the parent branch from which it was branched out of.

Continuous Delivery
Continuous Delivery leverages off of automated tests. In this scenario, the developer has a consistent pipeline to deploy their application as regularly as possible. It is always encouraged to regularly do small releases and monitor feedback for quicker troubleshooting. However, this practice normally requires human intervention.
Continuous Deployment
In Continuous Deployment, changes merged with the production branch are packaged and deployed without human intervention and in essence cutting release time from days to minutes.
Bitbucket Pipelines
Bitbucket Pipelines is a CI/CD service that ships with Bitbucket that enables automated building, testing, and deployment from within Bitbucket.
The underlying magic is the usage of containers to build and package artifacts. We can use our own images to run builds. You can checkout out an overview of building applications .
At the core Bitbucket Pipelines is bitbucket-pipelines.yml file. This is a configuration-as-code file that is versioned along with your code.
Let’s dive into the file itself and dissect the bits that facilitate build.
Each pipeline is split into steps and the maximum number of steps is currently at 10.
Each step runs commands in a separate container instance, this implies that one can use different Docker images for different steps.
A pipeline is run depending on the context. Currently there 5 supported contexts. Only one context can be run at a time, depending on the commit.
Contexts are defined in the pipelines section of the bitbucket-pipelines.yml and must have unique names, otherwise the default context is run.
-
default: All commits are run under this context unless the commit match any of the following pipeline contexts. -
branches: This context, if set, runs pipelines commits that match the specified branch.

-
tags/bookmarks: This context runs pipelines for all commit tags that match a tag/bookmark pattern. -
pull-requests: This pipeline context runs when there’s a pull request to the repo branch. -
custom: This a manually triggered pipeline.
image: python:3.7
definitions:
services:
mongo:
image: mongo
pipelines:
default:
- step:
name: Testing
caches:
- pip
script:
- pip install pymongo
- python -m unittest discover tests/
services:
- mongo
Let’s take a look at some of the pipeline definitions. Take the following sample for reference.
The script haspython.sh is as shown. It just checks for the Python interpreter and version.
| #!/bin/bash | |
| if ! hash python; then | |
| echo "Python is required to run some of these tests" | |
| exit 1 | |
| fi | |
| pyver=$(python -V 2>&1 | sed 's/.* \([0-9]\).\([0-9]\).*/\1\2/') | |
| if [[ "$pyver" -lt "27" || "$pyver" -gt "30" ]] | |
| then | |
| echo "This script requires Python 2.7.X installed. Found Python " "$pyver" | |
| fi |
options : These are global settings that apply to the whole pipeline.
image : Defines the docker image to be used through-out the pipeline. One can override this per-step or per definition.
pipelines : defines the pipeline and the steps to run. Should always have a definition.
default : This will execute all defined pipeline commands except Mercurial bookmarks, tags and branch-specific pipeline definitions.
step : This is build execution unit with the following properties:
image: The Docker image to runmax-time: Maximum number of minutes that a step can runcaches: The cached dependencies to useservices: Separate docker containers to use during buildartifacts: The files to be shared between stepstrigger: Defines whether a step will require human intervention or should run automatically. Default is automatic. Note that the build might be stopped to facilitate manual processes.
parallel : This enables you to run multiple steps at the same time

script : These are the commands to execute in sequence. Large scripts should be executed from script files.
branches : This section defines branch-specific builds commands to your pipelines. This will always override default unless otherwise. One can use glob patterns to capture matching branches.
pull-requests : This executes build commands to be run on pull-request. Initially, the changes will be merged first before the PR pipeline starts. If merge fails, the pipeline will stop. Forks don’t trigger pipelines.
pipes : New features, aims at simplify manual tasks by just simply supplying variables.
Bitbucket Tips and Tricks
- To prevent unnecessary triggering of pipelines, use
[skip ci]or[ci skip]as part of your commit message

- Use YAML anchors to avoid repetition in your pipelines configuration.
- You can speed up builds immensely by using
services, this avoids having to spin up multiple Docker images per step - Read the docs